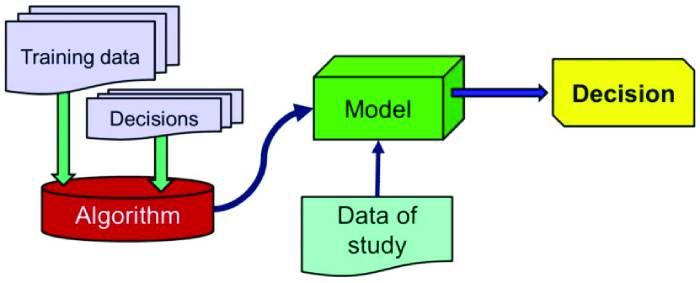
Supervised learning is a type of machine learning in which
an algorithm learns from labeled training data to make predictions or decisions
without human intervention. In supervised learning, the algorithm is provided
with a dataset in which both the input features and the corresponding target
outputs are known. The goal is to learn a mapping from the inputs to the
outputs so that the algorithm can make accurate predictions on new, unseen
data. There are various supervised learning algorithms, each with its own
strengths and weaknesses. Here are some samples of managed learning algorithms:
Linear Regression:
Linear regression is used for modeling the relationship
between a dependent variable (target) and one or more independent variables
(features) by fitting a linear equation.
It is commonly used for tasks like predicting house prices,
stock prices, and other continuous numerical values.
Logistic Regression:
Logistic regression is used for binary classification tasks,
where the goal is to classify data points into one of two classes (e.g., spam
or not spam, yes or no).
It models the probability of a data point belonging to a
particular class using a logistic function.
Random Forest:
Random forests are ensembles of decision trees.
They combine the guesses of multiple result trees to improve
exactness and diminish overfitting.
It finds the hyperplane that best separates data points of
different classes, maximizing the margin between them.
K-Nearest Neighbors (K-NN):
K-NN is a simple algorithm for both classification and
regression tasks.
It classifies data points by the majority class among their
k-nearest neighbors in the feature space.
Naive Bayes:
Naive Bayes is often used for text classification, such as
spam detection or sentiment analysis.
Neural Networks:
Neural networks, including feedforward, convolutional, and
recurrent neural networks, are used for a wide range of tasks, including image
recognition, natural language processing, and speech recognition.
They consist of interconnected artificial neurons organized
in layers.
Gradient Boosting Machines:
Gradient Boosting methods, such as Gradient Boosting Trees
(GBT) and XGBoost, are used for regression and classification tasks.
They build an ensemble of weak models (usually decision
trees) and iteratively improve their predictions.
Linear Discriminant Analysis (LDA):
LDA is used for dimensionality reduction and classification
tasks.
It finds linear combinations of features that best separate
classes in the data.
Elastic Net:
Elastic Net is a regularization technique used in linear
regression.
It combines L1 (Lasso) and L2 (Ridge) regularization to
prevent overfitting.
Ridge Regression:
Ridge regression is used to mitigate multicollinearity in
linear regression.
It adds L2 regularization to the linear regression cost
function.
Lasso Regression:
Lasso regression is used for feature selection and reducing
the impact of irrelevant features in linear regression.
It adds L1 regularization to the linear regression cost
function.
Gaussian Processes:
Gaussian processes are used for regression tasks,
particularly in scenarios with limited data.
They model the entire distribution of the target variable.
Bayesian Networks:
Bayesian networks are used for modeling the probabilistic
relationships between variables.
They are especially useful for decision-making under
uncertainty.
Reinforcement Learning:
Reinforcement learning is used for training agents to make
sequences of decisions to maximize a reward.
It is applied in robotics, game playing, and autonomous
systems.
Multiclass Classification Methods:
Algorithms like Multinomial Logistic Regression, One-vs-All
(One-vs-Rest), and Softmax Regression are used for classifying data into
multiple classes.
Ordinal Regression:
Ordinal regression is used when the target variable is
ordered or ranked.
It is suitable for tasks like rating prediction and customer
satisfaction analysis.
Time Series Forecasting Models:
Methods like ARIMA (AutoRegressive Integrated Moving
Average) and LSTM (Long Short-Term Memory) networks are used for predicting
future values in time series data.
Survival Analysis:
Survival analysis is used for predicting the time until an
event of interest occurs, often in medical and reliability studies.
Each of these supervised learning algorithms has its own
applications, assumptions, and characteristics. The choice of algorithm depends
on the specific problem and the nature of the data. Data scientists and machine
learning engineers select the most appropriate algorithm after careful
consideration of the dataset and the desired outcome.
What are the different types of classification algorithms?
Classification algorithms are used in supervised learning to
categorize data into predefined courses or labels. Some mutual types of cataloguing
systems include:
Binary Classification: Separates data into two classes, such
as yes/no, spam/not spam, or positive/negative.
Multi-Class Classification: Categorizes data into more than
two classes, like classifying animals into mammals, birds, reptiles, and more.
Multi-Label Classification: Assigns multiple labels or
classes to each data point, allowing for complex categorization.
Imbalanced Classification: Deals with datasets where one
class is significantly underrepresented, requiring specialized techniques to
address class imbalance.
Probabilistic Classification: Provides probability scores
for each class to measure the likelihood of data points belonging to a specific
class.
These classification algorithms are used in a wide range of
applications, including image recognition, sentiment analysis, and medical
diagnosis.



Comments
Post a Comment